Imputations
Contents
Imputations¶
Imputing land value to the FRS¶
No UK dataset directly estimates land value alongside income, but we connected multiple government sources to estimate it:
2019 National Balance Sheet estimates (NBS) contains land value by sector (Table C, column W).
2016-2018 Wealth and Assets Survey (WAS) contains income, demographics, and wealth by asset type (but not land value).
2019-2020 Family Resources Survey (FRS) contains income, benefits, and demographics (but not wealth); it is the core dataset for most distributional analysis.
We started by combining the NBS summary with the WAS to estimate land value for each household in the WAS. Of the £5.7 trillion in total land value, the NBS reports that £3.9 trillion is held by households, £1.6 trillion is held by corporations, and the remaining £200 billion is held by governments.
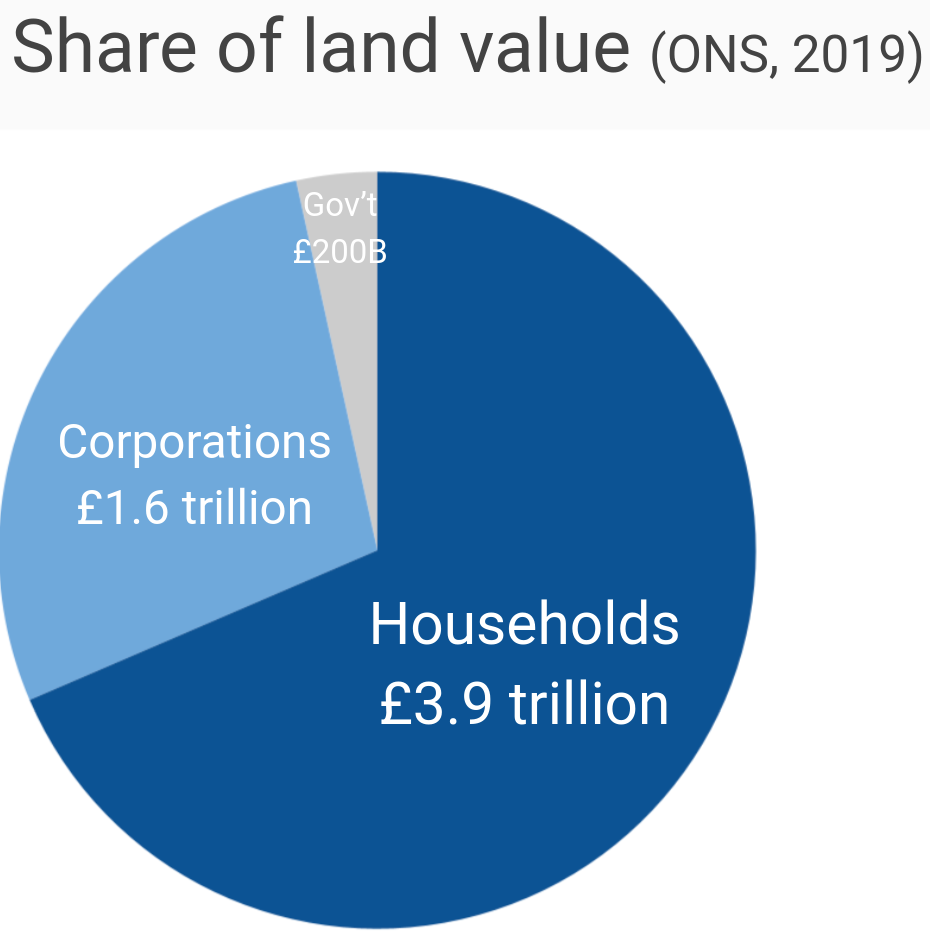
The WAS, meanwhile, sums to £6.2 trillion in property wealth and £4.9 trillion in corporate wealth. Dividing the respective values shows that households have 62p of land for each £1 in property wealth, and 33p of land for each £1 in corporate wealth. We estimate the land value of each household using these factors, producing land value that sums to the £5.5 trillion in non-government land wealth.
| Household | Property wealth | Corporate wealth | Estimated land value |
| 1 | £x | £y | 0.62x + 0.33y |
| ... | ... | ... | ... |
| Total | £6.2tn | £4.9tn | £5.5tn |
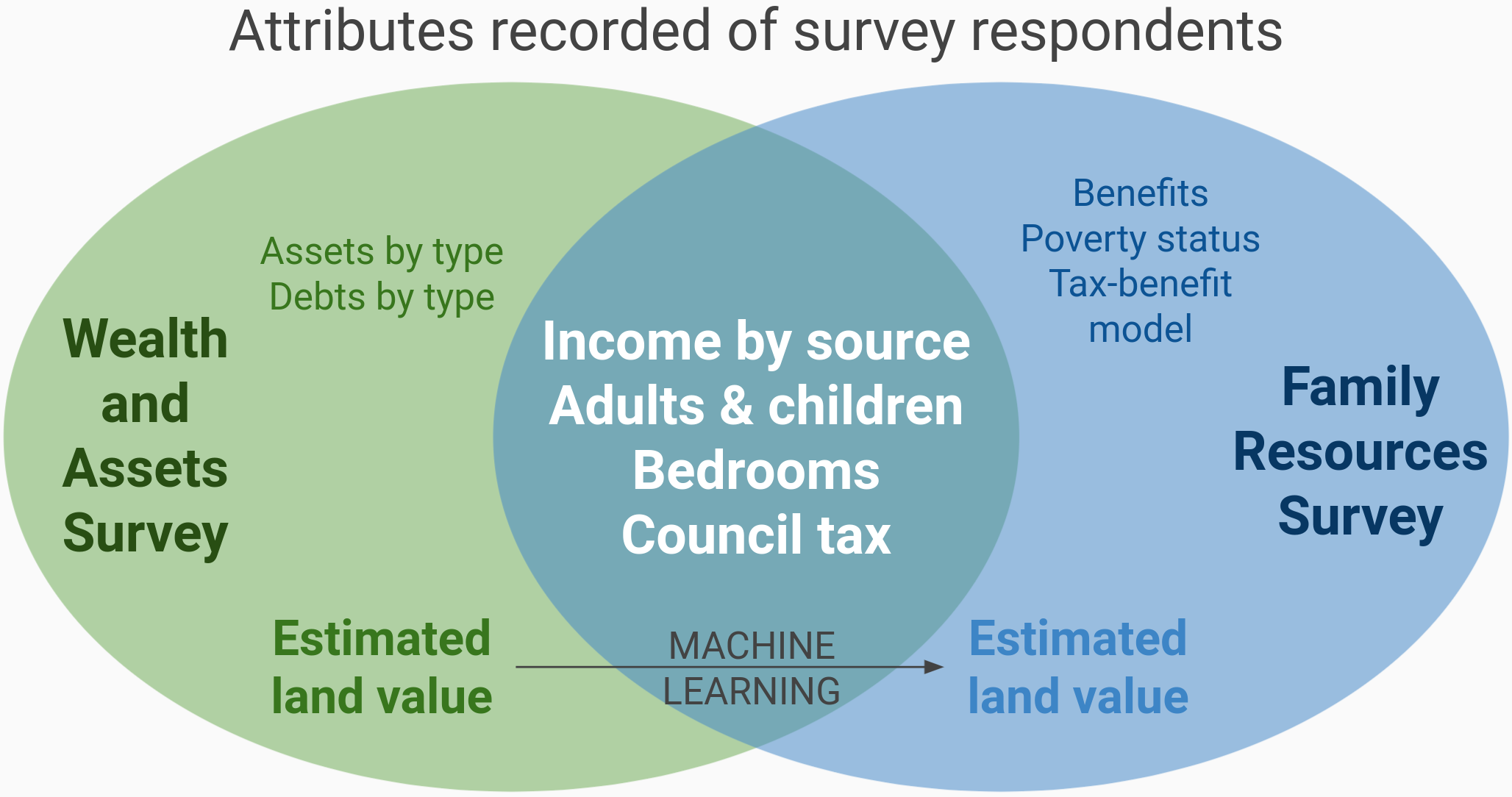
Given the estimated land value for each household in the WAS, our next task was to map it to households in the FRS, the core dataset for our analysis. We applied our synthimpute Python package, which imputes data from one source to another using skewed random forests quantile regression. Specifically, we built a nonparametric prediction model from the WAS of land value, based on several household characteristics common to the WAS and FRS1, then used that model to sample from each FRS household’s predicted distribution. To ensure that the total in the FRS matched the £5.5 trillion in land value, we introduced bias to sample from the predicted distribution using the Beta distribution.
We’re working on improvements to the land imputation:
Uprating WAS data to account for wealth growth from 2018 to 2020
Reporting model quality by summarizing quantile loss on a holdout set
Imputing carbon emissions to the FRS¶
The Family Resources Survey does not contain consumption information on its respondents. However, the Living Costs and Food Survey does, and we can use it to estimate carbon emissions.
To do this, we also use the official estimates of the UK’s carbon footprint. These estimate the carbon emissions produced by each category of consumption. ncfs_emissions_2019.csv contains these estimates for 2019, along with their category names and COICOP codes. We use these estimates to estimate the carbon emissions produced by each household first in the LCFS, then in the FRS.
To estimate emissions produced by households in the LCFS, we use the shared categories of consumption: finding the total expenditure by households for each major category from the LCFS, and the total emissions produced by each category from the carbon footprint estimates. Then, we divide the emissions by the expenditure to find the carbon intensity of each category - the tonnes of C02 associated with each pound spent, per category. With this, we mutliply each households’s expenditure in each category by that category’s carbon intensity to find the total emissions produced by that household.
LCFS households share some variables with FRS households:
Number of adults
Number of children
UK region
Employment income
Self-employment income
State pension
Pension income
Similarly to land value, we fit a random forest model to predict carbon emissions from those predictors in the LCFS, then sample from the predicted distribution for FRS households to estimate the emissions produced by each household in the FRS.
- 1
Our model of WAS land value used the following predictors: gross income, number of adults, number of children, pension income, employment income, self employment income, investment income, number of bedrooms, council tax, and whether the household rents.